I've been doing some more work on the concepts developed for Clay-Pidgin: A TCP based message queuing for Tcl/Tk. While I like to play up the game engine aspects, most of my immediate needs for it are far less glamorous.
I work for a small company who runs very large simulations for the US, Australian, and South Korean Navies. While the software is the same for each customer, the environments we run the simulations on are very, very different. The simulations are different as well. While each tends to center around a ship and its crew, some Navies are hiring us to build crew instructional material. Some hire us to evaluate a design for survivability against a broad range of threats. Some want to measure the effectiveness of a new technology on an existing ship.
While each of these uses may involve running the simulation thousands of times, the simpler forms of analysis can be run in an afternoon on a laptop. The more involved jobs can keep a room full of computers busy for months. Having a technology that can scale from threads in the same process, to multiple processes running in parallel on the same computer, to multiple processes running across a network of computers is what is driving my research.
We currently have a UDP based system for our job dispatch system that works well in a locked room, running across computers with fixed IP addresses. As we have branched out into other environments, we have pretty much stepped on every rake along the road of progress. Goofy things like streaming services running on unlisted ports, firewalls that inhibit UDP multicast, and the insanity of managing RPC across a DHCP network.
It currently works by each "blade" running a small program that advertises its presence on the network via UPD multicast.

Each party in our current scheme opens up a Remote Procedure Call (RPC) port and advertises it's presence with a little home-brewed zeroconf-like system. When we want to kick off a new task, dispatch finds an idle blade, and gives it all of the instructions for how to run the task (including downloading files, etc.) via RPC. Is this an ideal setup? Oh heavens no. It was a weekend bodge job that's taken on a life of its own, and at the time I wasn't sure what we needed it to do, so RPC was viewed as a way to leverage flexibility as we prototyped out the other working parts.
From a network security perspective, the current setup is a living nightmare. From an actual day-to-day performance standpoint, this is a jalopy. From a diagnostic perspective this is F'ng magic. But not the working kind. The Lovecraftian product of a cruel demon sort of magic.
Pidgin is simplifying this work considerably. In years of using our existing system, we know, for instance, that we generally run all jobs from a central location. The ability to have blades discover dispatchers and dispatchers discover blades is an unneeded complexity. (In my defense, that was an unknown during our initial design.) So if we can forgo that complexity, we can simplify our network architecture thus:

Note the file access section. One things I discovered in the process of developing a thread communication mechanism is that I can forgo sockets entirely. I'm realizing that with the right magic, I can even avoid sockets for clients running on the same computer. They can all communicate via files. Multiple projects can attach themselves to the same sqlite database without issue. And that opens up the possibility for different constituencies to each have their own PIDGIN interface.
For my dispatch program, I actually have two different constituencies that need to maintain communications. One is the dispatch server tracking the progress of jobs which are broken into tasks. The other is within the task I have multiple federates (and a GUI as well as a logger) which need to communicate across multiple processes and threads as well.
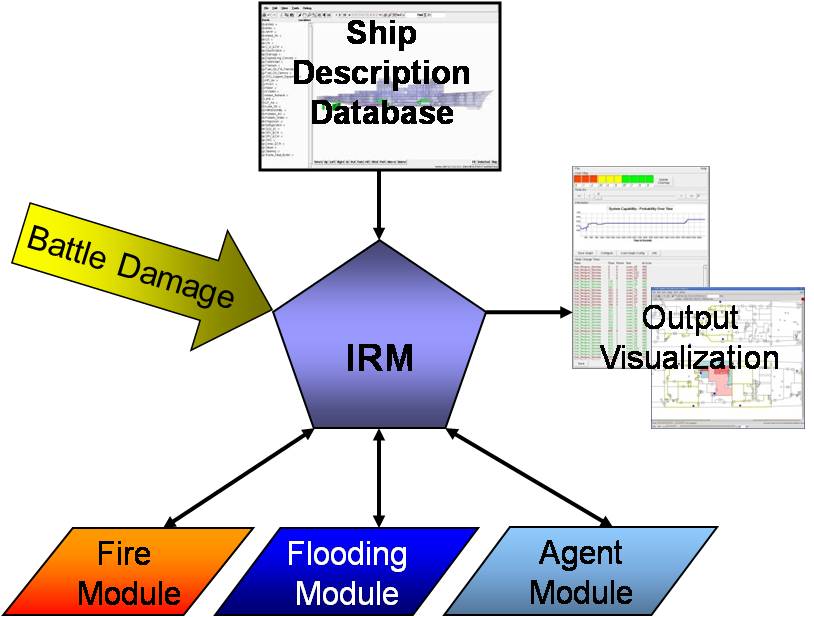
Currently I employ a host of cooperative multitasking techniques to try to keep as much of the Integrated Recoverability Model running inside of one thread of one process as possible. The trade off is that while I can run multiple processes in parallel, each individual process is restricted to considering one federate at a time. At least for the internal federates. Our Fire an Flooding models are external fortran based programs.
With pidgin I can move to an architecture where each federate is running in an independent thread. The GUI can be an independent thread. We can finally make the best use of computers with more than one core.